We propose a new method to build landmark map which is efficient and interpretable. We explore the possibility of using attention-based neural network to determine which pixels are relevant to camera pose estimation, which shows quite a good result.

A toy level demonstration. (a)color image (b)depth image (c) Pseudo color illustrates the learned landmarks which from LandmarkNet.
Red regions show where LandmarkNet pays attention to (d) The learned landmarks are labelled on the 3D occupancy grid map.
LandmarkNet is able to focus on objects that can be used as landmarks, such as book, dice and plant. Image regions corresponding to these objects can be used to build landmark map, ignoring redundant information.
We implement LandmarkNet based on PyTorch and our code will be publicly available at [code]
Contributions
Flexibility
LandmarkNet is a multi-task neural network. It also performs camera pose regression and image semantic segmentation concurrently. We can extract landmarks from the designated region of the image by network parameter adjustment flexibly.
Optimality
This method is based on the regression model of input sensor information and output pose, so our choice of landmark is based on the optimization of the projection between robot pose and input image. It is different from the traditional method, the results can accurately reflect that those landmarks are needed for real robot positioning, so as to delete redundant feature information.
Interpretability
The landmark obtained by this method is a part of 3D map, such as poster, fire hydrant or a part of building, and is not meaningless geometric features such as point, line, or corner.
System
·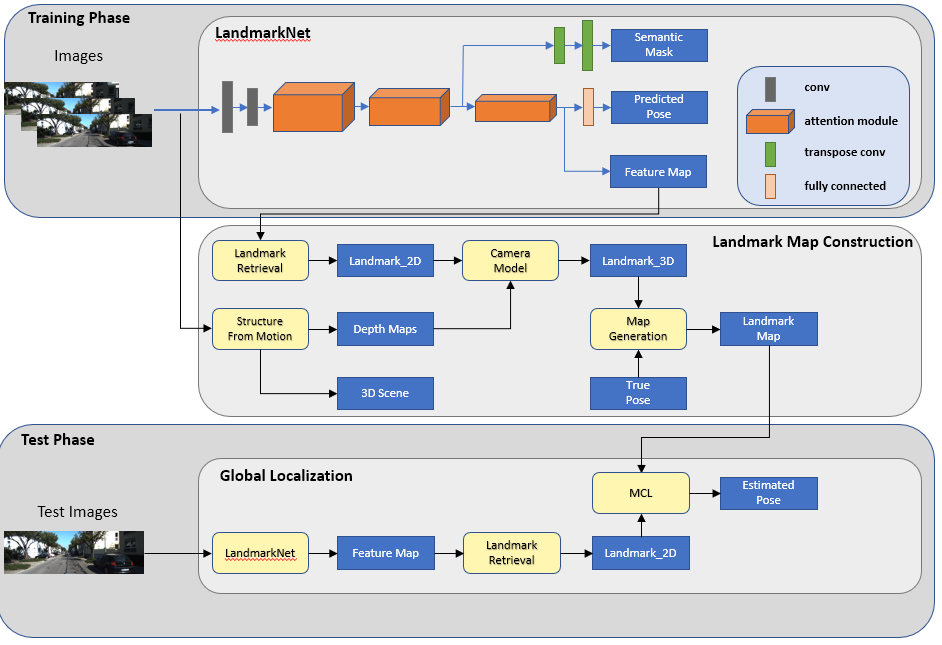
Landmark Learning System
Our work can be divided into 3 parts, LandmarkNet training, landmark map construction and Monte Carlo localization. We train an attention-based neural network called LandmarkNet to obtain feature maps, which represent the importance of image pixels. With obtained feature maps, we use multi-view geometry to compute the depth of image pixels that are highly relevant to camera pose estimation. Landmark map is built based on camera pose and depth of image pixels. Monte Carlo localizato is performed based on landmark map built using our method.
LandmarkNet
We use residual attention mechanism to build LandmarkNet, which predicts semantic segmentation mask and camera pose simutaneously. This allows LandmarkNet to focus on regions that are related to the task of semantic segmentation and pose regression. These regions will later be used to build landmark maps.
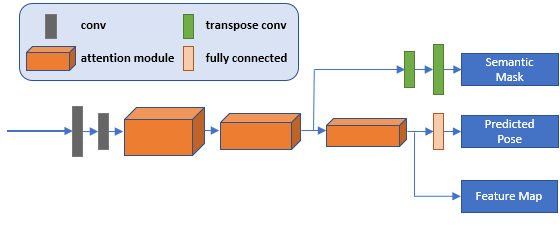
|
|
Architecture of LandmarkNet |
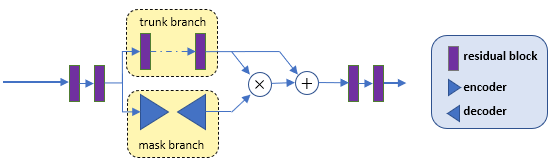
Residual Attention Block |
The network is composed of three residual attention blocks, transpose convolution layers and a fully connetect layer. With each residual attention block, there are two branches, which predicts feature maps and the importance of feature map separately. Feature map after the second residual attention block is later used to determine the importance of image pixels
Map Construction

Landmark Map of KITTI Dataset. (a)Landmark map generated using our method. Compared with dense map, our landmark map keeps only meaningful regions.
(b) Partially enlarged raw dense map. (c)Partially enlarged landmark map built using our method
We compute depths of image pixels that are related to camera pose estimation. With these image pixels and their corrresponding depths, we build landmark map by back projecting image pixels into 3D space. Redundant pixels are eliminated in built landmark map.
Localization
We use Monte Carlo method to perform localization using our landmark map. Landmarks in the landmark map are projected into 2D sapce based on hypothetical camera pose and the fitness of hypothetical pose is determined by comparing projected landmarks and captured image.